MMPedestron论文分析
- 论文标题:When Pedestrian Detection Meets Multi Modal Learning Generalist Model and Benchmark Dataset
- 作者:Yi Zhang , Wang Zeng , Sheng Jin , Chen Qian Ping Luo , and Wentao Liu
- 单位:Tsinghua University,SenseTime Research and Tetras.AI,The University of Hong Kong,Shanghai AI Laboratory
研究动机
- 多模态感知的潜力与挑战:现有方法大多是“专科型模型”(specialist models),只针对单一模态或某一对模态设计,缺乏统一的、通用的“全科型模型”(generalist model)。
- 缺乏通用模型的问题:需要一种能够 统一处理多种模态及其动态组合 的检测模型。
- 数据基准不足:多模态、特别是包含事件相机(Event)的综合大规模基准数据集缺失。没有系统性的数据基准,也限制了多模态行人检测的研究发展。
为克服现有行人检测方法对单一或有限模态的依赖,构建一个能够处理多模态输入并适应不同模态组合的通用模型,同时弥补缺乏多模态大规模基准数据集的问题。
文章贡献
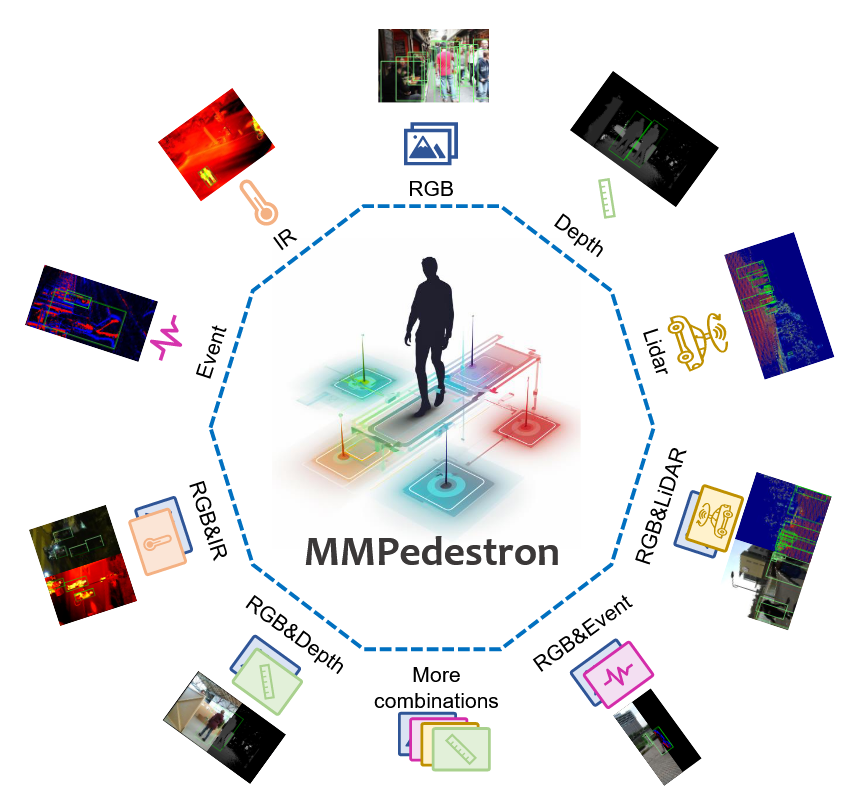
上图可以看到MMPedestron统一了多种模态输入,包括RGB、IR、Event、Depth和LiDAR,用于行人检测。
提出了 MMPD 数据集
- 构建了首个大规模、多模态行人检测基准数据集,整合了现有公开数据集(RGB、IR、Depth、LiDAR 等),并新采集了 EventPed 数据集 以弥补社区缺乏 RGB-Event 数据的空缺。
- 数据集在 模态多样性(RGB、IR、Depth、LiDAR、Event 及其组合)和 场景多样性(监控、自动驾驶、机器人、室内外场景)两方面均具备丰富性,从而支持对通用模型的系统性评估。
首次提出了“通用多模态行人检测模型”概念
- 提出了 MMPedestron 模型,能够处理多种输入模态及其动态组合,而不仅仅局限于单模态或固定模态对。
- 模型在设计上强调 灵活性(flexibility)、可扩展性(scalability) 和 跨场景泛化能力(generalization ability)。
显著的性能提升
- 在多个行人检测基准上达到了 state-of-the-art 的性能,超过了专为某一模态设计的现有模型。
- 与大规模模型(如 InternImage-H)相比,能以更小的参数规模实现可比性能。
文章方法论
统一多模态编码(Unified Multi-modal Encoder)
- 将不同模态的输入转化为视觉 token。
- 在 token 序列中引入了两个额外的可学习 token:
- MAA(Modality Aware Abstractor):用于抽象不同模态的特征表征。
- MAF(Modality Aware Fuser):用于自适应融合多模态特征。
- 得到的混合 token 序列经过 Transformer blocks 处理后,由 modality unifier 模块统一为共享表示。
通用检测头(General Detection Head)
- 统一后的 token 特征被传递至通用检测头,用于行人检测任务的最终预测。
- 与传统针对特定模态的检测头不同,这一检测头是模态无关的。
训练策略
- 在多模态数据上进行联合训练(multi-modal joint training),使模型能学到跨模态的共享特征表示。
- 能够处理模态缺失的场景,克服了以往方法假设“所有模态都可用”的局限。
统一多模态编码(Unified Multi-modal Encoder)
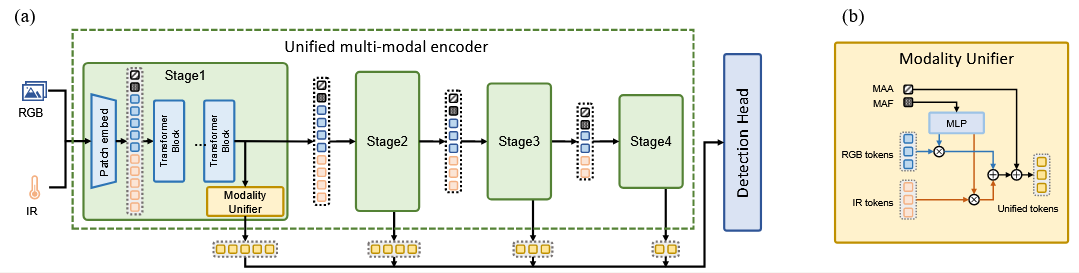
与以往为不同模态设计独立分支的方法不同,MMPedestron 采用统一的 Transformer 编码器来处理所有模态数据,该编码器采用四阶段的分层结构,每一阶段包含模态特定的 patch embedding、堆叠的 Transformer blocks 以及模态统一器;输入数据首先通过模态特定的 patch embedding 转换为视觉 token,并在序列前加入两个可学习的 token,即模态感知抽象器(MAA)和模态感知融合器(MAF),用于捕捉输入模态组合的特征信息,随后这些多模态视觉 token 与 MAA、MAF 共同形成混合序列,经由 Transformer blocks 进一步建模,其中采用了性能与效率兼顾的 dual vision transformer block;这种统一编码器设计在参数共享下更轻量,能够跨模态学习通用知识并提升泛化能力,同时借助注意力机制实现更高效和全面的信息交互。
模态统一策略
由于多模态视觉 token 的存在,传统检测头难以有效利用这些特征。为此,作者提出了一个 模态统一器(modality unifier module),将混合 token 转换为与单模态视觉 token 相同格式的统一 token,从而便于检测头处理。
在这个模块中引入了两个可学习的辅助 token:
- MAF(Modality-Aware Fuser):负责评估不同模态的重要性。通过一个 MLP 对 MAF 特征进行处理,得到各模态的置信度分数,用于加权融合多模态 token。
- MAA(Modality-Aware Abstractor):负责收集输入模态的领域知识,并在融合后的统一 token 中补充这些信息。
简单介绍一下MAF和MAA的工作原理,引入两个辅助 token:
- 计算模型置信度
MAF token 的特征记为 $x_{MAF}$。作者用一个多层感知机(MLP)处理它,得到每个模态的置信度 $c$:
$$ c = \sigma(\text{MLP}(x_{MAF})) $$
其中:
- $\sigma$ 表示 Sigmoid 函数,保证输出在 $[0,1]$。
- $c = [c_1, c_2, …, c_m]$ 表示每个模态的重要性分数。
-
统一 token 的融合公式
融合时,每个模态的 token 特征为 $X_i$,对应的置信度为 $c_i$,有效性标志为 $w_i$:
$$ X_{uni} = \frac{\sum_{i=1}^{m} (w_i \cdot c_i \cdot X_i)}{\sum_{i=1}^{m} w_i} + x_{MAA} $$
解释:
- 如果某个模态存在,$w_i = 1$,否则缺失时 $w_i = 0$。
- $\sum (w_i \cdot c_i \cdot X_i)$ 表示对有效模态的特征按其置信度加权平均。
- $\sum w_i$ 是归一化,避免模态数量不一致带来的偏差。
- $x_{MAA}$ 是 MAA token 提供的额外模态知识,被直接加到融合结果里。
-
整体效果
通过这个设计:
- MAF 动态调节每个模态的贡献(谁更重要,权重大)。
- MAA 补充模态相关的全局知识。
- 这样得到的 $X_{uni}$ 就是“统一 token”,与单模态 token 格式一致,检测头可以直接使用。
最终具体做法是:如果某个模态缺失,就用空 token 填充并置权重为 0;若模态存在,则置权重为 1。最终,统一 token 由各模态特征按重要性加权平均得到,再加上 MAA 的信息。这样,模型就能 自适应地调整不同模态的贡献,充分利用各模态的互补信息,同时提升对模态特性的理解和利用能力。
训练策略
MMPedestron 的训练分为两个阶段:
- 首先在大规模的 RGB 数据集(Objects365-Persons、COCO-Persons 和 CrowdHuman)上进行预训练,以学习人体的一般知识;
- 随后在 CrowdHuman、LLVIP、InOutDoor、STCrowd 和新建的 EventPed 等多模态数据集上进行训练,使模型掌握多模态特征。
所有模态都被视为二维图像输入,其中 LiDAR 点云被投影为稀疏深度图,事件数据则通过时间区间积分转化为图像。与以往为每个模态单独设计分支的方法不同,MMPedestron 借助 MAA 与 MAF 机制,用单一共享分支处理所有模态,从而显著减少参数量。为提升模型适应性,我们设计了模态随机丢弃策略,以概率 $p$ 随机去掉部分模态,使模型既能学习单模态特征,又能处理多模态组合;当某个模态缺失时,用空图像填充并在编码过程中屏蔽其对应的 token。训练目标方面,分类采用质量焦点损失与交叉熵损失,回归采用 GIOU 损失和 L1 损失,遵循主流检测框架的实践。
实验分析
文章对 MMPedestron 在多个具有挑战性的数据集上进行了全面评估,既测试了单模态性能,也考察了多模态融合效果,同时通过跨数据集迁移实验验证了模型的泛化能力。
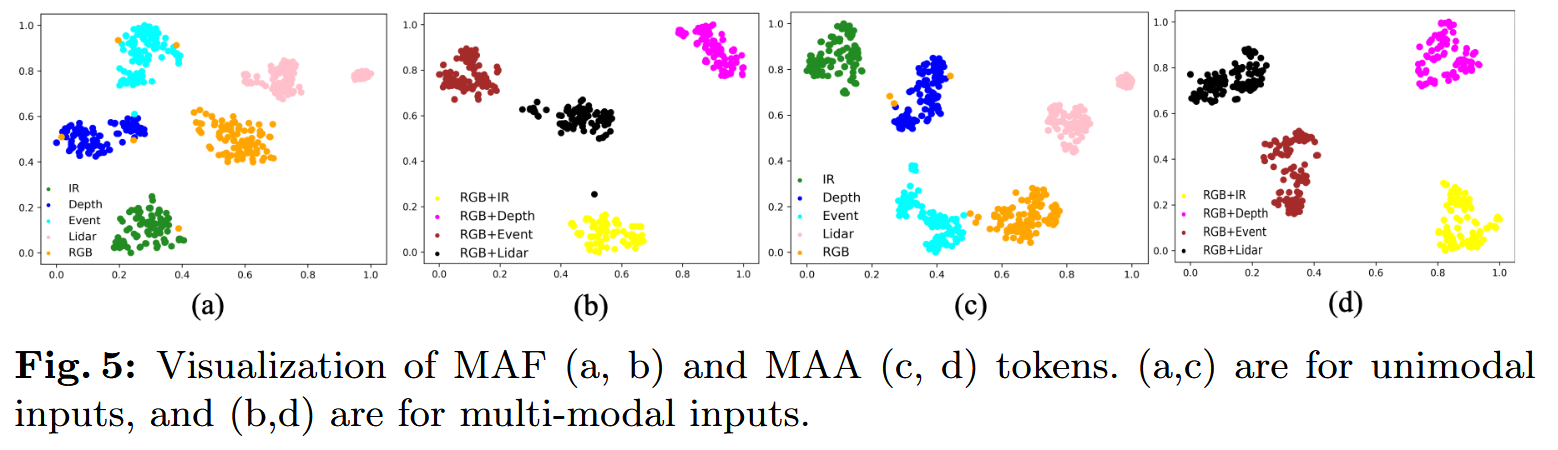
通过对模型进行消融实验,验证了MAF和MAA的有效性。且通过绘制输入输出为单模态或双模态的特征分布时,使用 t-SNE 可视化了不同输入模态下的 token 特征分布。结果显示,当输入为单模态时,MAF 和 MAA 的特征呈现明显的聚类,对应各自的模态,表明它们能够根据输入模态自适应调整特征;当输入为多模态组合时,也能形成可区分的聚类模式。这种模态感知能力使 MMPedestron 能根据具体的模态组合动态选择融合策略,从而保证模型在多种模态及其组合下的良好泛化能力。