A2S2K-ResNet的论文分析
提出背景
为了使神经元有效地调整感受野大小和跨通道依赖性,本文提出了基于注意力的自适应频谱空间核改进的剩余网络,其中的改进点有几个:
- attention-based adaptive spectral–spatial kernel
- improved spectral–spatial ResNet
设计较新的模型结构
- EFR module
- A2S2K-Net’s block
网络总体结构
网络总体结构图
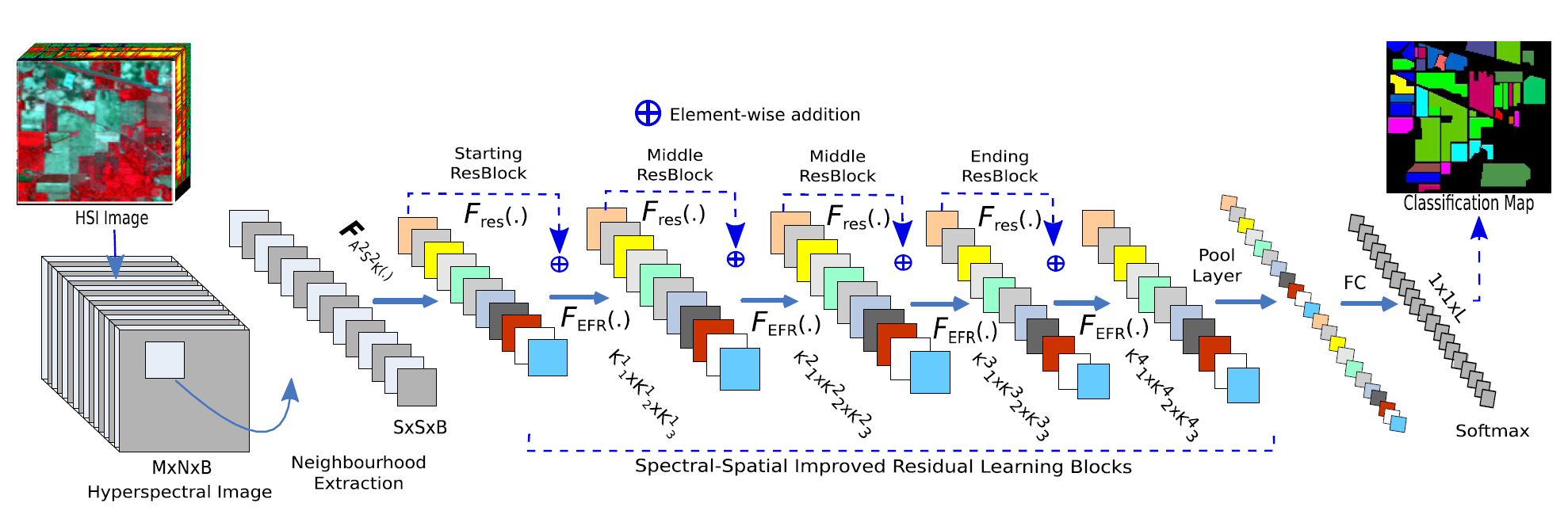
分为A2S2K-block、ResNet block、Pool Layer、输出层。将重点阐述前两个模块。
A2S2K-block
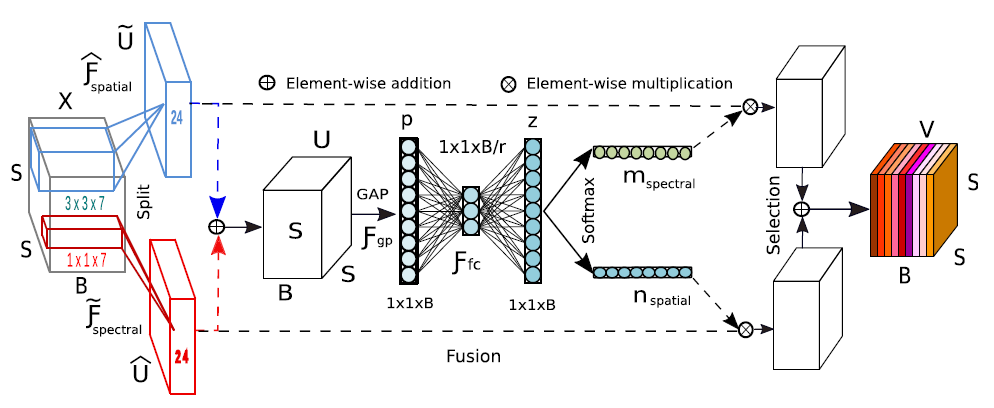
来自于Selective kernel networks,及通过attention操作将不同卷积核提取的特征进行自适应选取。其网络结构涉及到三个部分:
- Split:生成具有各种内核大小的多个路径,这些大小对应于神经元的不同感受野大小。
- Fuse:组合并汇总来自多个路径的信息,以获得选择权重的全局和全面表示。
- Select:根据选择权重聚合大小不同的内核的特征图。(及相加操作)
代码片段如下:
# 上层卷积
x_1x1 = self.conv1x1(X)
x_1x1 = self.batch_norm1x1(x_1x1).unsqueeze(dim=1)
# 下层卷积
x_3x3 = self.conv3x3(X)
x_3x3 = self.batch_norm3x3(x_3x3).unsqueeze(dim=1)
# concat操作
x1 = torch.cat([x_3x3, x_1x1], dim=1)
# 加和(初步融合特征)
U = torch.sum(x1, dim=1)
# 全局池化操作,为了将特征进行融合和便于之后的attention操作
S = self.pool(U)
# 通过3D卷积进行特征融合
Z = self.conv_se(S)
attention_vector = torch.cat(
[
# 通过3D卷积进行扩张
self.conv_ex(Z).unsqueeze(dim=1),
self.conv_ex(Z).unsqueeze(dim=1)
],
dim=1)
# softmax是为了将空间和维度的比例进行统一划分
attention_vector = self.softmax(attention_vector)
# 所谓乘上attention后的结果进行权重自适应调整
V = (x1 * attention_vector).sum(dim=1)
EFR Module
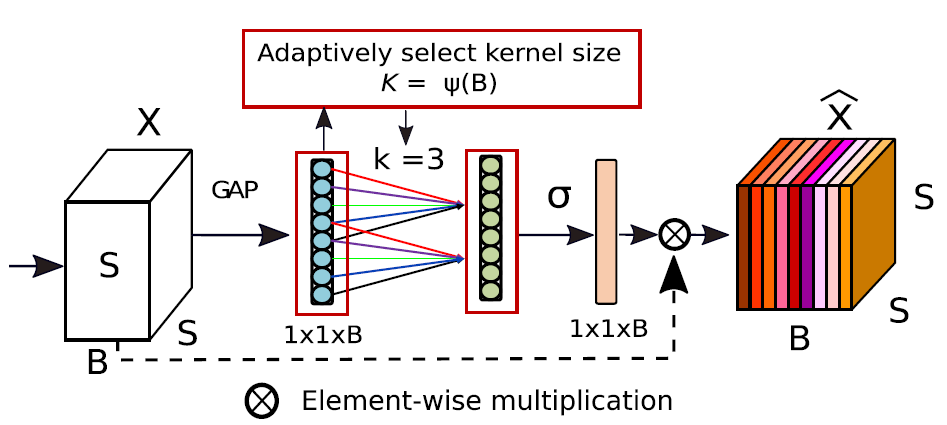
就是特征重提取,本模块来自于SENet中的SEA模块,为了在之后能够对卷积后相对重要的特征进行进一步的重提取,可以有效减少网络层数,提升速度。(SENet也是SKNet的主要参考论文)。
改进残差网络
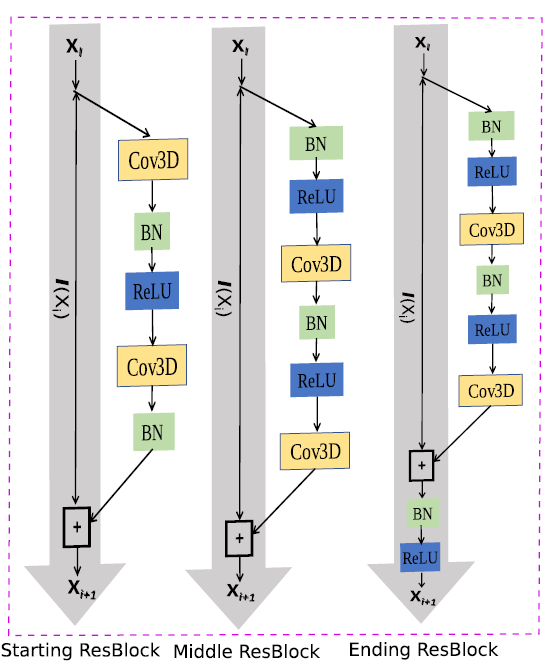
原论文没有提及为什么这么改,我觉得就是为了让3D卷积后面接一个BN和激活函数,让层之间保持这样跨层关系?
代码
网络代码
A2S2K-blockclass S3KAIResNet(nn.Module):
def __init__(self, band, classes, reduction):
super(S3KAIResNet, self).__init__()
self.name = 'SSRN'
self.conv1x1 = nn.Conv3d(
in_channels=1,
out_channels=PARAM_KERNEL_SIZE,
kernel_size=(1, 1, 7),
stride=(1, 1, 2),
padding=0)
self.conv3x3 = nn.Conv3d(
in_channels=1,
out_channels=PARAM_KERNEL_SIZE,
kernel_size=(3, 3, 7),
stride=(1, 1, 2),
padding=(1, 1, 0))
self.batch_norm1x1 = nn.Sequential(
nn.BatchNorm3d(
PARAM_KERNEL_SIZE, eps=0.001, momentum=0.1,
affine=True), # 0.1
nn.ReLU(inplace=True))
self.batch_norm3x3 = nn.Sequential(
nn.BatchNorm3d(
PARAM_KERNEL_SIZE, eps=0.001, momentum=0.1,
affine=True), # 0.1
nn.ReLU(inplace=True))
self.pool = nn.AdaptiveAvgPool3d(1)
self.conv_se = nn.Sequential(
nn.Conv3d(
PARAM_KERNEL_SIZE, band // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True))
self.conv_ex = nn.Conv3d(
band // reduction, PARAM_KERNEL_SIZE, 1, padding=0, bias=True)
self.softmax = nn.Softmax(dim=1)
self.res_net1 = Residual(
PARAM_KERNEL_SIZE,
PARAM_KERNEL_SIZE, (1, 1, 7), (0, 0, 3),
start_block=True)
self.res_net2 = Residual(PARAM_KERNEL_SIZE, PARAM_KERNEL_SIZE,
(1, 1, 7), (0, 0, 3))
self.res_net3 = Residual(PARAM_KERNEL_SIZE, PARAM_KERNEL_SIZE,
(3, 3, 1), (1, 1, 0))
self.res_net4 = Residual(
PARAM_KERNEL_SIZE,
PARAM_KERNEL_SIZE, (3, 3, 1), (1, 1, 0),
end_block=True)
kernel_3d = math.ceil((band - 6) / 2)
# print(kernel_3d)
self.conv2 = nn.Conv3d(
in_channels=PARAM_KERNEL_SIZE,
out_channels=128,
padding=(0, 0, 0),
kernel_size=(1, 1, kernel_3d),
stride=(1, 1, 1))
self.batch_norm2 = nn.Sequential(
nn.BatchNorm3d(128, eps=0.001, momentum=0.1, affine=True), # 0.1
nn.ReLU(inplace=True))
self.conv3 = nn.Conv3d(
in_channels=1,
out_channels=PARAM_KERNEL_SIZE,
padding=(0, 0, 0),
kernel_size=(3, 3, 128),
stride=(1, 1, 1))
self.batch_norm3 = nn.Sequential(
nn.BatchNorm3d(
PARAM_KERNEL_SIZE, eps=0.001, momentum=0.1,
affine=True), # 0.1
nn.ReLU(inplace=True))
self.avg_pooling = nn.AvgPool3d(kernel_size=(5, 5, 1))
self.full_connection = nn.Sequential(
nn.Linear(PARAM_KERNEL_SIZE, classes)
# nn.Softmax()
)
def forward(self, X):
# A2S2K-block
x_1x1 = self.conv1x1(X)
x_1x1 = self.batch_norm1x1(x_1x1).unsqueeze(dim=1)
x_3x3 = self.conv3x3(X)
x_3x3 = self.batch_norm3x3(x_3x3).unsqueeze(dim=1)
x1 = torch.cat([x_3x3, x_1x1], dim=1)
U = torch.sum(x1, dim=1)
S = self.pool(U)
Z = self.conv_se(S)
attention_vector = torch.cat(
[
self.conv_ex(Z).unsqueeze(dim=1),
self.conv_ex(Z).unsqueeze(dim=1)
],
dim=1)
attention_vector = self.softmax(attention_vector)
V = (x1 * attention_vector).sum(dim=1)
# res-net block
# start block
x2 = self.res_net1(V)
# middle block
x2 = self.res_net2(x2)
# 防止过拟合
x2 = self.batch_norm2(self.conv2(x2))
x2 = x2.permute(0, 4, 2, 3, 1)
x2 = self.batch_norm3(self.conv3(x2))
# middle block
x3 = self.res_net3(x2)
# last block
x3 = self.res_net4(x3)
x4 = self.avg_pooling(x3)
x4 = x4.view(x4.size(0), -1)
return self.full_connection(x4)
model = S3KAIResNet(BAND, CLASSES_NUM, 2).cuda()
summary(model, input_data=(1, img_rows, img_cols, BAND), verbose=1)
剩下的代码太多了,详情前往代码处查看。